Customers Feedback Analysis using NLP - The Netflix Use Case
In the era of digitalization, Most companies have various sources of customers feedback, social media, call logs, mobile apps, to name a few. Therefore, analyzing such feedback to come up with actionable insights, is becoming essential for any business with an online presence.
1. Introduction
Some of the challenges businesses face while analyzing customers feedback is the qualitative nature of the data and sometimes the huge amount of feedback they get. Ratings are quantitative and hence can be easily analyzed, however analyzing textual feedback, reviews, and free text is challenging. Likely, today we have Natural Language Processing and Machine Learning to efficiently process large amount of text without human intervention.
There are mainly two approaches that can be used to find topics in text data, Topic Modeling, or Text Clustering. In this tutorial, we will go through some techniques and ideas about the two approaches and try to understand what people are talking about in mobile app reviews. We will start by fetching some reviews data, taking as an example Netflix’s mobile app, then we will apply a series of preprocessing techniques to prepare the data for topic detection.
2. Data Preparation
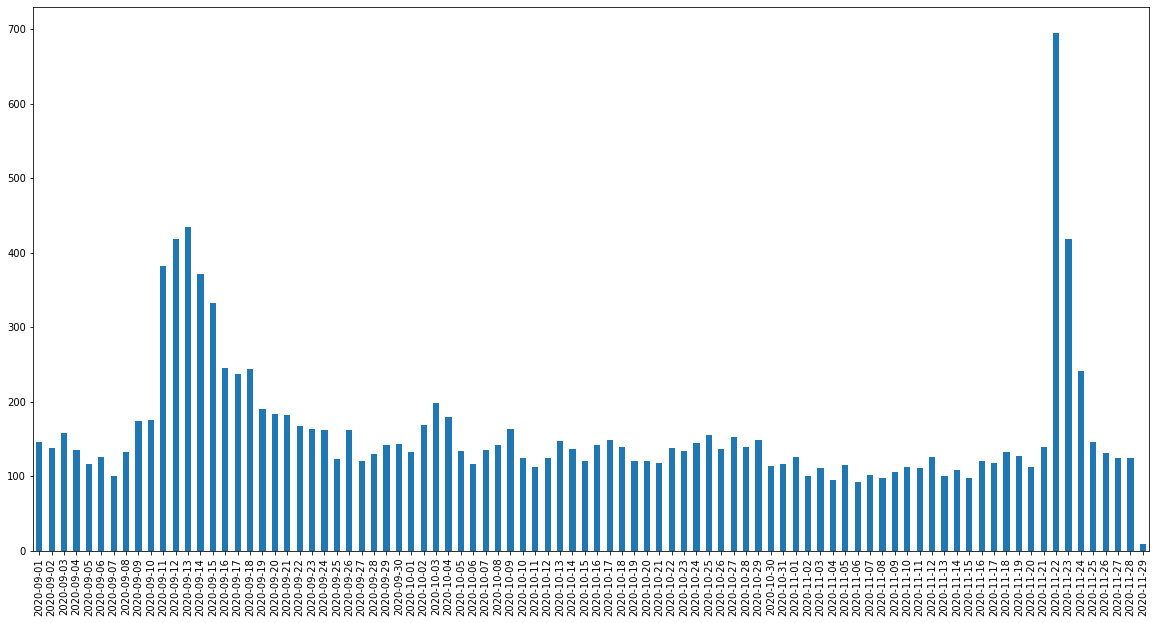
In the following analysis, I used a dataset of 5000 recent reviews from the Netflix mobile app on Google Play. The following figure shows the daily number of reviews with a score of 1, it gives us an idea about the amount of data we are dealing with.
We can also look at the review length distribution. As we can see, usually people submit short to medium size reviews (under 50 words).
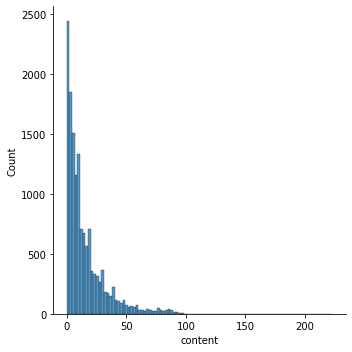
I used a maximum length of 48 word for all reviews, longer reviews are discarded from the dataset.
3. Data Preprocessing
Text preprocessing is an important step for natural language processing. It transforms text into a more digestible and usable form so that machine learning algorithms can perform better.
In our case, I applied the following transformation:
- Remove URLs, emails, phone numbers & punctuations.
- Remove tags, emojis, symbols & pictographs.
- Remove stop words.
- Convert to lowercase and lemmatization.
- Duplicates removal.
- Spell checking.
- Non-English reviews removal.
Once preprocessing is done, we can look at a random review example.
1
2
Original review: {'It has all the boring movies and episodes'}
Preprocessed review: {'boring movie episode'}
4. Reviews Topics Modeling
In topic modeling, a topic is defined by a cluster of words with their respective probabilities of occurrence in the cluster. The goal is to find the topics in a set of documents, without having prior knowledge about those topics. In most cases, we only need to specify the number of topics and leave the rest of the algorithms.
4.1 Latent Dirichlet allocation (LDA)
Probably the most popular topic modeling approach, it treats each document (text) as a mixture of topics and each word in a document is considered randomly drawn from the document’s topics. The topics are considered hidden (thus the ‘Latent’ in the name) which must be uncovered through analyzing joint distribution to compute the conditional distribution of hidden variables (topics) given the observed variables, words in documents. This takes into consideration the fact that documents can have an overlap of topics which is somehow a typical case in the natural language.
I performed LDA for topic modeling using the amazing library gensim, and also use it to tokenize the data and prepare dictionary and bag-of-words features.
In order to have a good LDA model, we need to find a suitable number of topics that gives good quality topics. One of the commonly used approaches to evaluate topics is measuring the Topic Coherence, it’s a single score by topic where it measures the degree of semantic similarity between high scoring words in the topic. These measurements help distinguish between topics that are semantically interpretable and topics that are artifacts of statistical inference. I used C_v measure which is based on a sliding window, one-set segmentation of the top words and an indirect confirmation measurement that uses normalized pointwise mutual information (NPMI) and the cosine similarity. Read more about coherence measures here.
I ran multiple LDA models with different number of topics, and picked the one with the highest score. We could also finetune other hyperparameters like document-topic density (alpha) or word-topic density (beta), however, I keep it simple and only finetune the number of topics.
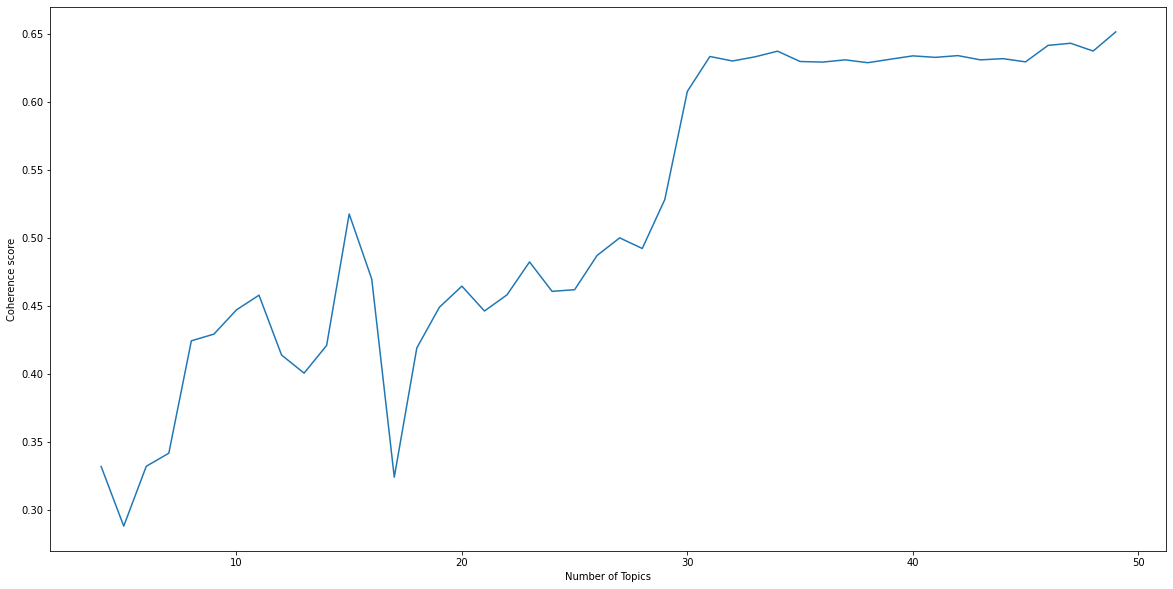
We pick the number of topics with the highest coherence score: K=30

As we can see, we got many topics related to technical issues about the app, controversies and people not satisfied with the app. we will dig deeper into the clusters in the next approaches.
Despite its popularity and usefulness in the context of medium and large documents, LDA generally performs poorly with short documents. In our case, reviews are generally short texts (> 50 word) with typically one topic, which is not necessary LDA’s assumption. In order to solve this issue, we will try out a Short Text Topic Modeling.
4.2. Short Text Topic Modeling
In order to model topics in short texts, we use an altered LDA approach called Gibbs Sampling Dirichlet Mixture Model (GSDMM) where the main assumptions are :
- Each document corresponds to only one topic.
- The words in a document are generated using one unique topic.
The GSDMM model can be explained with a process called the Movie Group Process, where a professor is leading a film class and students are randomly seated at K table. Students are asked to make a shortlist of their favorite movies and each time a student is called, he or she must select a new table regarding the two following conditions:
- The new table has more students than the current table.
- The new table has students with similar lists of favorite movies.
After repeating this process consistently, we expect that the students eventually arrive at an optimal table configuration. where some tables will disappear and others to grow larger to form clusters of students with similar movies’ interests.
We adapt rwalk’s implementation for our STTM.
we start with a K = 30 number of topics and let GSDMM find the optimal number of topics.

Similar to LDA, STTM did a good job in highlighting the main topics.
5. Reviews Categorization using Text Clustering
In this section, we will look into how Text Clustering can help with detecting topics and categorizing reviews. In clustering, the idea is to group documents, with potentially semantic similarities, into different groups. First, we represent each document with a numerical vector in a way similar documents should have closer vectors in the space (using a similarity metric). We will test out different approaches, from classic ones like tf-idf to recent and advanced ones around the idea of documents embedding.
5.1 Features & Embeddings Extraction
a. TF-IDF & LDA
TF-IDF stands for Term Frequency — Inverse Document Frequency and is have been explained in many articles and tutorials in the data science community, but I will remaind you of the main formula :
\[tfidf(w,d,D) = tf(w,d) * idf(w,D)\]with : \(tf(w,d) = log(1+f(w,d))\) and \(idf(w,D) = log(N / f(w,D))\)
where :
- \(f(w,d)\) is the frequency of word w in document d.
- \(d\) is a document from our dataset
- \(w\) is a word in a document
- \(D\) is the collection of all documents
- \(N\) is the number of documents we have in our dataset
An other way to vectorize document is to use LDA features where each vector represent the probabilities of belonging to a topic. We fix number of topics to 20, for example, to have 20-dim vector for each review text item.
Sklearn made it easy to calculate TFIDF and LDA features.
b. Embeddings
Embeddings are low-dimensional learned continuous vector representations for words, sentences, or documents. They can be used in many use cases like finding similar documents, do machine learning on text and visualizing text and relationships.
For our use case, we want to represent reviews as vectors representation to be able to apply clustering algorithms to detect topics. Reviews are usually short sentences, thus, we should look for a suitable embedding approach for this situation.
Here is the list of the approaches I have tested :
- Sentence Transformers using BERT.
- Vanilla BERT :
- CLS token as an embedding
- Averaging last hidden layer outputs as an embedding
- Averaging the concatenation of last hidden layers outputs as an embedding
- Facebook’s InferSent :
- Using GloVe
- Using FastText
We will use the first approach with the model bert-large-nli-stsb-mean-tokens, as it showed the best performance in general.
In order to visualize the chosen embeddings, we should use a dimensionality reduction approach to represent reviews in the 2D space. We have many options like PCA, t-SNE, TriMap, AutoEncoders, and UMAP. I tried most of those techniques, but I will stick with UMAP as it’s is a dimension reduction technique that is gaining a lot of popularity recently.
We reduced the embeddings to 16 for better clustering, and we will use 2-dimension reduction for the visualization.
5.2 Clustering embeddings
Once features are ready, we can proceed with applying clustering algorithms to hopefully detect relevant topics in our reviews dataset. As we don’t know the number of topics, we will avoid using k-means, where it’s always programmically difficult to find the best K, and usually performs poorly if the assumptions on the shape of the clusters aren’t met.
As an alternative, we will use HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) which is a density-based clustering algorithm. HDBSCAN extends DBSCAN by converting it into a hierarchical clustering algorithm, and then using a technique to extract a flat clustering based on the stability of clusters.
We can summarize how HDBSCAN algorithm works in the following steps:
- Transform the space according to the density/sparsity via building the minimum spanning tree from the mutual reachability distances.
- Construct a cluster hierarchy of connected components
- Condense and extract the stable clusters from the condensed tree
To learn more about HDBSCAN, check this detailed article. Likely, we have a high performing implementation of HDBSCAN clustering that we can use to do our clustering.
HDBSCAN has a couple of major parameters that we need to tune to get good clusters. we will focus on two main parameters, min_cluster_size which should be set to the smallest cluster size that we wish to consider, and min_samples measures how clusters are conservative to the noisy points. You can read more about parameter selection for HDBSAN here.
Let’s fix those parameters and run the HDBSCAN on the embeddings. We choose min_cluster_size = 40 and min_samples = 10.
Now we can visualize the embeddings in a 2D space with their associated clusters to have an idea of how the clusters are dense.

In order to better evaluate clusters and highlight the best coherent ones, we will sort them by size (i.e, the number of reviews in a cluster), and the median outlier score for the items in the clusters. this score can be found in the attribute outlier_scores_ in the clusterer object. it provides a value for each sample in the original dataset that was fit with the clusterer. The higher the score, the more likely the point is to be an outlier. Let’s explore the results! we remove the clustering representing the noisy points and order the clusters by their size or how dense they are.

The figure shows the word cloud for each cluster detected by HDBSCAN, the title contains the cluster/topic number, the percentage, and the number of reviews belonging to that topic.
Few insights from the clusters :
- The biggest two clusters, (Topics 20,22) representing around 16% of all reviews, are related to the topic of boycott and controversy around the French movie ‘Cuties’.
- Another prominent cluster (Topic 35) is related to people experiencing issues when they open the Netflix app, especially after installing some updates.
- Topic 18 is mainly about people leaving negative reviews about the content on Netflix.
- Another recurrent issue reported many times is when the video freeze after certain number of seconds.
- A lot of reviews are related to hurting Hindu sentiments and promoting propaganda. Apparently, it’s about another controversy caused by Netflix.
- In some clusters, people are asking about more movies that aren’t currently available on Netflix, many of them are related to Bollywood movies.
- We can see many topics related to technical issues about the app :
- Issues with login.
- A black screen when playing a video.
- App crashing after the start.
- Payments can’t be processed. People requesting other payment methods (Rupay).
- Video/Audio isn’t working properly.
5. Conclusion
As we have seen, Natural language processing can be very useful when it comes to customer feedback understanding. We have used topic modeling and text clustering to detect relevant topicss in Netflix Android app review from Google Play. All mentioned approaches can be improved further through more hyperparameters finetuning. If you have any questions or comments, feel free to connect with me on LinkedIn.